|
北京2015年12月22日電 /美通社/ -- 企業級基礎云服務商青云QingCloud(www.qingcloud.com )日前宣布,基于Hadoop的大數據集群服務現已正式推出。該服務包括三大核心組件,即HDFS分布式文件系統、YARN任務調度和集群資源管理系統,以及MapReduce并行計算系統。通過QingCloud Hadoop集群服務,用戶能夠在2-3分鐘內創建一個Hadoop集群,并且可以進行橫向和縱向的在線伸縮,極大地降低了Hadoop平臺的技術門檻。

Hadoop是一個針對海量大數據進行存儲和處理的分布式開源平臺,在大數據領域的應用極為廣泛。它使用簡潔的MapReduce編程模型分布式處理跨集群的大型數據集,集群規模可以擴展到幾千甚至上萬。QingCloud Hadoop集群服務采用Master/Slave架構,由三種節點類型構成,即主節點(YARN Resource Manager和HDFS Name Node)、從節點(YARN Node Manager和HDFS Data Node),以及客戶端節點(Hadoop Client Node)。用戶在客戶端節點發起MapReduce任務,通過與HDFS和YARN集群中各節點的交互存取文件、執行MapReduce任務,最終獲取結果。

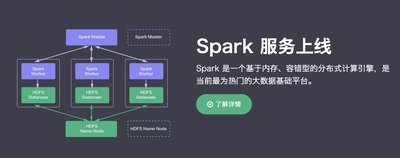
早在2015年8月,青云QingCloud就已推出基于Spark的大數據集群服務,此次Hadoop集群服務的上線是對QingCloud大數據基礎平臺的有力補充。Hadoop和Spark各有千秋,Hadoop適用于更大規模的離線數據處理,且對系統故障具備天然的抵抗力;Spark更適合做快速的實時數據分析。因此,用戶可以根據應用場景的不同,選擇靈活的大數據解決方案。
具體而言,青云QingCloud Hadoop集群服務具有以下特性:
青云QingCloud CTO甘泉(Reno Gan)表示,Hadoop集群服務的推出標志著QingCloud大數據基礎平臺的進一步完善,結合已經推出的Spark、ZooKeeper、消息隊列(Kafka)、Redis、Memcached、MongoDB等服務,QingCloud的大數據平臺服務已經能夠越來越靈活地滿足用戶的各種需求,實現用戶數據價值的較大化。