北京2023年11月27日 /美通社/ -- 11月27日,浪潮信息發布"源2.0"基礎大模型,并宣布全面開源。源2.0基礎大模型包括1026億、518億、21億等三種參數規模的模型,在編程、推理、邏輯等方面展示出了先進的能力。
當前,大模型技術正在推動生成式人工智能產業迅猛發展,而基礎大模型的關鍵能力則是大模型在行業和應用落地能力表現的核心支撐,但基礎大模型的發展也面臨著在算法、數據和算力等方面的諸多挑戰。源2.0基礎大模型則針對性地提出了新的改進方法并獲得了能力的提升。
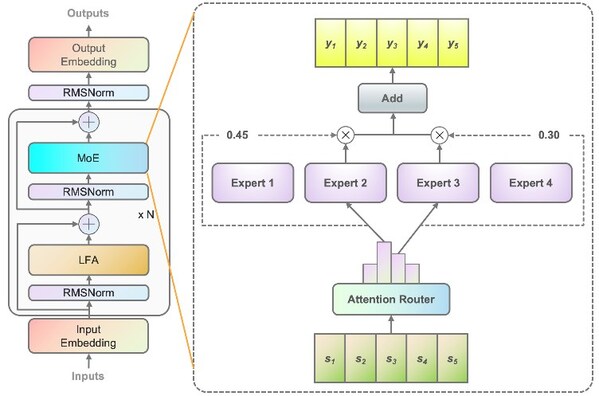
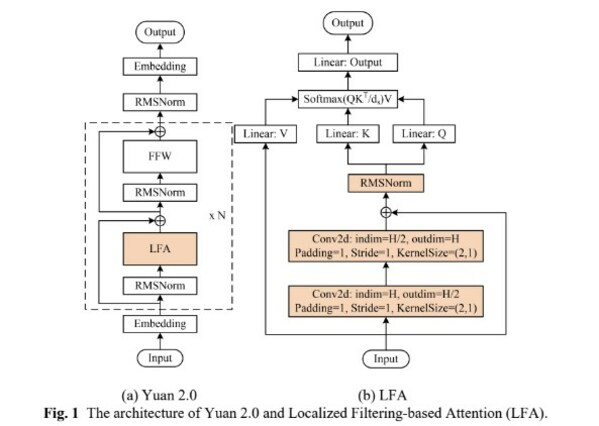
算法方面,源2.0提出并采用了一種新型的注意力算法結構:局部注意力過濾增強機制(LFA:Localized Filtering-based Attention)。LFA通過先學習相鄰詞之間的關聯性,然后再計算全局關聯性的方法,能夠更好地學習到自然語言的局部和全局的語言特征,對于自然語言的關聯語義理解更準確、更人性,提升了模型的自然語言表達能力,進而提升了模型精度。
數據方面,源2.0通過使用中英文書籍、百科、論文等高質量中英文資料,降低了互聯網語料內容占比,結合高效的數據清洗流程,為大模型訓練提供了高質量的專業數據集和邏輯推理數據集。為了獲取中文數學數據,我們清洗了從2018年至今約12PB的互聯網數據,但僅獲取到了約10GB的數學數據,投入巨大,收益較小。為了更高效地獲得相對匱乏的高質量中文數學及代碼數據集,源2.0采用了基于大模型的數據生產及過濾方法,在保證數據的多樣性的同時也在每一個類別上提升數據質量,獲取了一批高質量的數學與代碼預訓練數據。

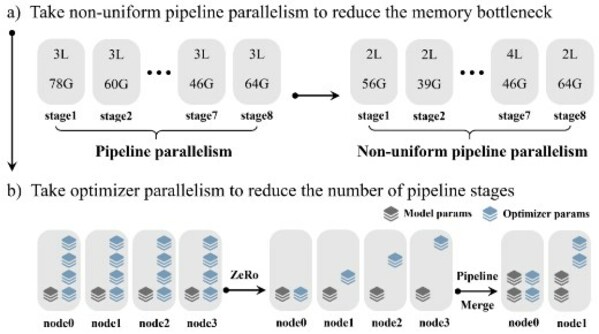
算力方面,源2.0采用了非均勻流水并行的方法,綜合運用流水線并行+優化器參數并行+數據并行的策略,讓模型在流水并行各階段的顯存占用量分布更均衡,避免出現顯存瓶頸導致的訓練效率降低的問題,該方法顯著降低了大模型對芯片間P2P帶寬的需求,為硬件差異較大訓練環境提供了一種高性能的訓練方法。
源2.0作為千億級基礎大模型,在業界公開的評測上進行了代碼生成、數學問題求解、事實問答方面的能力測試,測試結果顯示,源2.0在多項模型評測中,展示出了較為先進的能力表現。
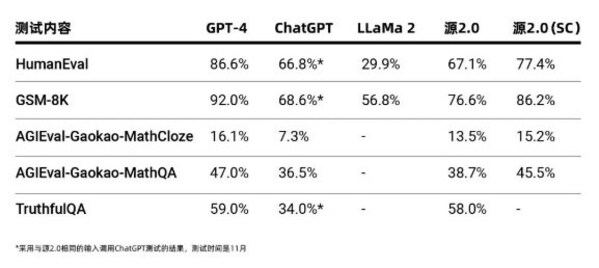
源2.0采用全面開源策略,全系列模型參數和代碼均可免費下載使用。
代碼開源鏈接
https://github.com/IEIT-Yuan/Yuan-2.0
論文鏈接
https://github.com/IEIT-Yuan/Yuan-2.0/blob/main/docs/Yuan2.0_paper.pdf