北京2024年4月15日 /美通社/ -- 4月11日,國家互聯網信息辦公室公開發布第五批深度合成服務算法備案信息,浪潮信息開發的"源"大模型算法已完成備案并獲公布。

根據《互聯網信息服務深度合成管理規定》,具有輿論屬性或者社會動員能力的深度合成服務提供者,應當按照《互聯網信息服務算法推薦管理規定》履行備案和變更、注銷備案手續。目前,深度合成算法服務備案和生成式AI服務備案是國家對人工智能領域進行監管的兩種主要規定,分別面向技術服務與應用服務,旨在規范和促進生成式AI健康、有序、繁榮發展。
浪潮信息較早布局開展大模型算法開發,2021年發布2457億參數的"源1.0"中文語言大模型,2023年成功研發并開源千億參數"源2.0"基礎大模型。
"源2.0"基礎大模型包含1026億、518億、21億三種參數規模,在代碼編程、邏輯推理、數學計算等多方面展示出了先進的能力。
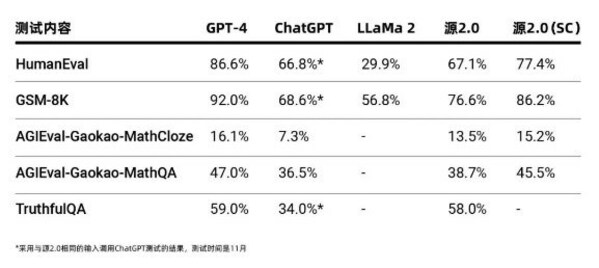
在業界公開的評測上,"源2.0"進行了代碼生成、數學問題求解、事實問答方面的能力測試。結果顯示,源2.0在多項模型評測中,展示出了較為先進的能力表現。
"源2.0"大模型采用全面開放開源的策略,全系列模型參數和代碼均可免費下載使用。自發布以來,"源2.0"大模型不斷進行版本更新,持續在代碼能力、數理邏輯、推理速度等方面進行深度優化,同時提供豐富的預訓練、微調以及推理服務腳本,并和LlamaFactory、FastChat、LangChain、LlamaIndex等框架工具全面適配,助力研發人員高效完成開發部署工作。
目前,浪潮信息基于"源2.0"大模型設計開發了效率工具"YuanChat",支持在AI PC端以對話形式調用大模型,幫助用戶完成數據計算、公文寫作、編程設計、知識問答、會議紀要、文本總結與摘要等各類任務,讓用戶輕松、便捷地享受本地化部署的大模型能力,提升AI生產效率!
未來,浪潮信息將持續更新"源2.0"系列基礎大模型能力,結合自身技術優勢和應用落地實踐,推動開源大模型的技術迭代與繁榮生態建設,加速大模型賦能千行百業。













